Elang Documentation & Quick Start¶
The 5-min Guide to Word Embeddings¶
If you have a Word2Vec model and would like to generate a 2-dimensional word embedding visualization, this can be done through the plot2d function:
from elang.plot.utils import plot2d
from gensim.models import Word2Vec
model = Word2Vec.load("path.to.model")
plot2d(model)
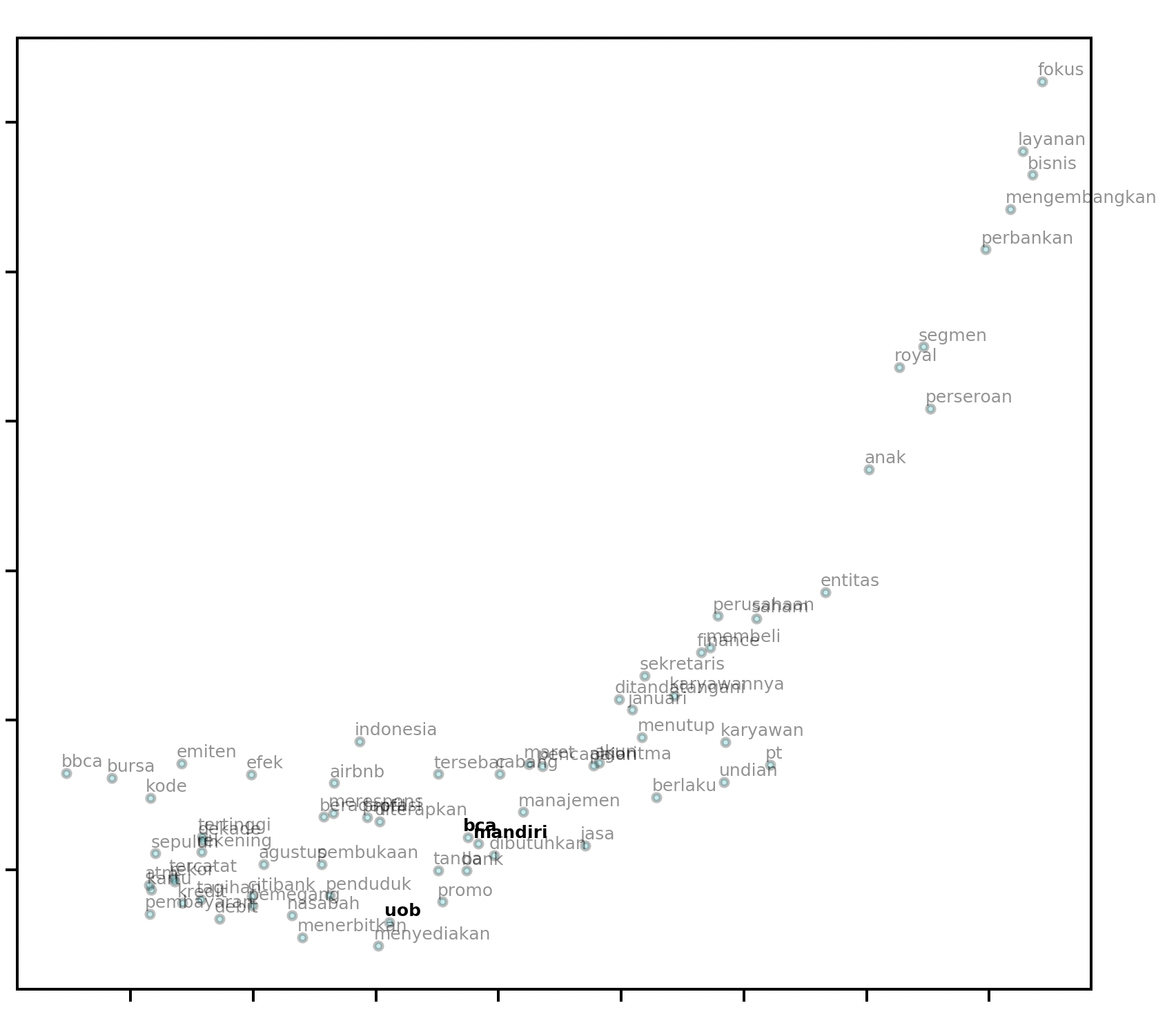
The default method for dimensionality reduction (to obtain exactly two dimensions) is T-SNE. This, and the other parameters can be specified as optional parameters.
For example, you may not wish to plot all the words in your Word2Vec model, and only wish to see a list of words. This can be done using the words parameter;
You may optionally wish to bring attention to a small subset of words within the plot, and this can be done using the targets parameter.
We will also specify methods to be “PCA” instead of “T-SNE” (default), resulting in the following function call:
from elang.plot.utils import plot2d
list_of_words_to_appear = ["bca", "mandiri", "uob", "algoritma", "airbnb", ..., "emiten"]
plot2d(model,
# method for dimensionality reduction
method="TSNE",
# only show following words in the final plot
words=list_of_words_to_appear,
# target words are given special emphasis in the final plot
targets=['uob', 'mandiri','bca']
)
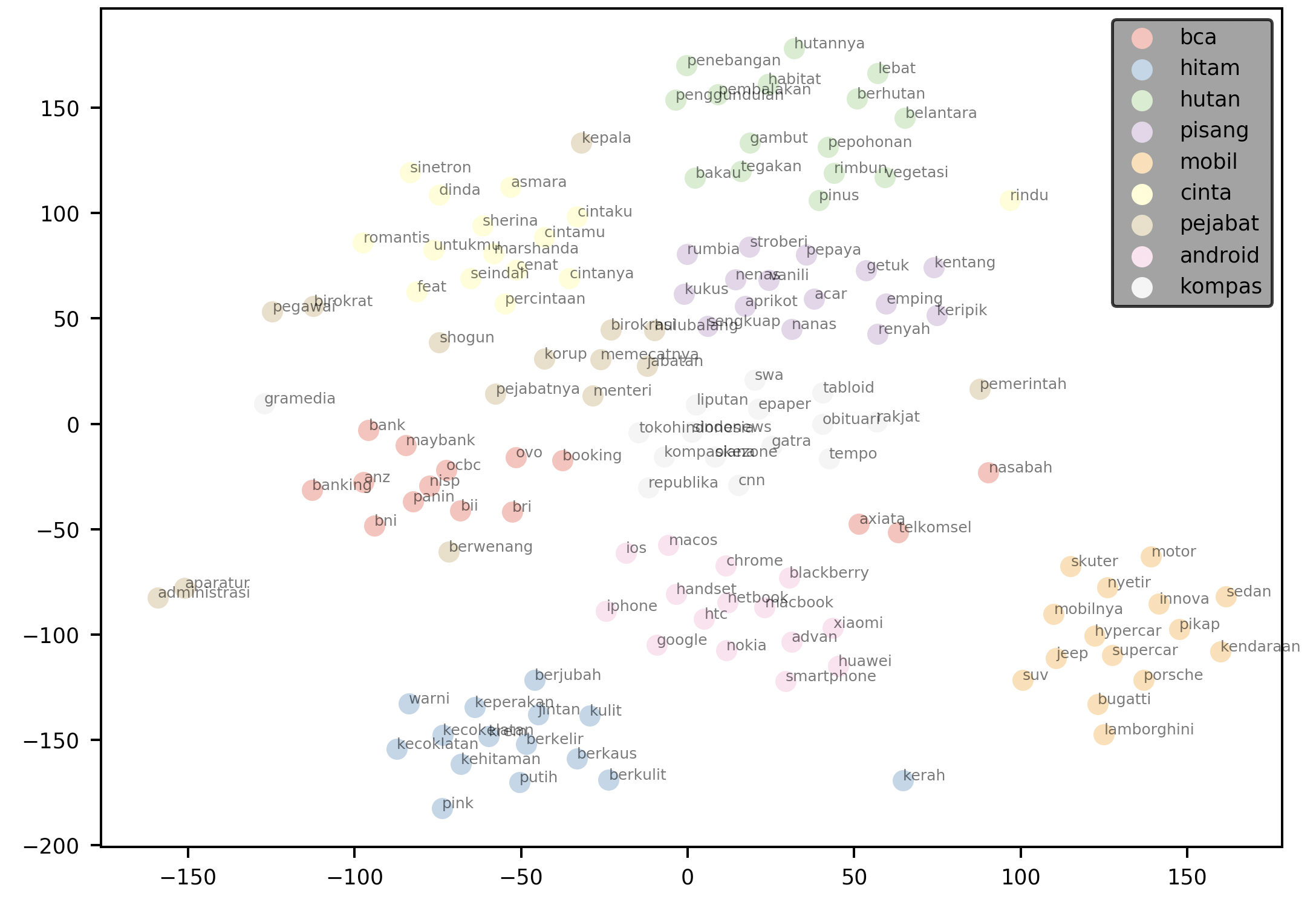
elang also includes visualization methods to help you visualize a user-defined k number of neighbors to each words.
When draggable is set to True (default False), you will obtain a legend that you can move around in the resulting plot.
from elang.plot.utils import plotNeighbours
model = Word2Vec.load("path.to.model")
words = ['bca', 'hitam', 'hutan', 'pisang', 'mobil', "cinta", "pejabat", "android", "kompas"]
plotNeighbours(model,
words,
method="TSNE",
k=15,
draggable=True)
The code plots the 15 nearest neighbors for each word in the supplied words argument. It then renders the plot with a draggable legend.
Just like the case of plot2d, it uses “T-SNE” as the default method for dimensionality reduction. This can be overriden via the method parameter.
The 5-min Guide to NLP Preprocessing¶
Elang comes with a number of pre-processing functions to make cleaning data in Bahasa Indonesia a little easier.
The remove_* group of functions parses a string and eliminate any occurrences of words in a pre-determined list (negative list).
from elang.word2vec.utils import *
x = "Oh ya, saya sudah pernah ke Hutan Ingatan Pasar Seni, Bandung, Senin 25 Maret kemarin. Tempat ini bagus anjir."
x = remove_stopwords_id(x)
# x: "Saya pernah ke Hutan Ingatan Pasar Seni, Bandung, Senin 25 Maret kemarin. Tempat bagus anjir."
x = remove_region_id(x)
# x: "Saya pernah ke Hutan Ingatan Pasar Seni, Senin 25 Maret kemarin. Tempat bagus anjir."
x = remove_calendar_id("Hutan Ingatan Pasar Seni, Bandung, Senin 25 Maret")
# x: "Saya pernah ke Hutan Ingatan Pasar Seni kemarin. Tempat bagus anjir."
x = remove_vulgarity_id(x)
# x: "Saya pernah ke Hutan Ingatan Pasar Seni kemarin. Tempat bagus."
FAQs¶
1. Can I use the library to visualize my word embeddings trained using English corpus (instead of Indonesian)?¶
Answer:
Yes. There are no inherent assumptions about the model. plot2d and plotNeighbors will take a Word2Vec model and a supplied list of words and generate your plot.
In practice, your model may be trained from a mixed set of languages and they won’t matter as long as the underlying representation for each word vector remain consistent.